TL;DR We propose a text-guided dual-level image editing framework for rectified flow transformers, enabling fine-grained and coarse editing by
leveraging semantically interpretable attention outputs.

We propose a text-guided image editing approach on rectified flow transformers, such as Flux. Our method can generalize to semantic edits on different domains such as humans, animals, cars, and extends to even more complex scenes such as an image of a street (third row, first example). FluxSpace can apply edits described as keywords (e.g. "truck" for transforming a car into a truck) and offers disentangled editing capabilities that do not require manually provided masks to target a specific aspect in the original image. In addition, our method does not require any training and can apply the desired edit during inference time.
Abstract
Rectified flow models have emerged as a dominant approach in image generation, showcasing impressive capabilities in high-quality image synthesis. However, despite their effectiveness in visual generation, rectified flow models often struggle with disentangled editing of images. This limitation prevents the ability to perform precise, attribute-specific modifications without affecting unrelated aspects of the image. In this paper, we introduce FluxSpace, a domain-agnostic image editing method leveraging a representation space with the ability to control the semantics of images generated by rectified flow transformers, such as Flux. By leveraging the representations learned by the transformer blocks within the rectified flow models, we propose a set of semantically interpretable representations that enable a wide range of image editing tasks, from fine-grained image editing to artistic creation. This work offers a scalable and effective image editing approach, along with its disentanglement capabilities.
Method
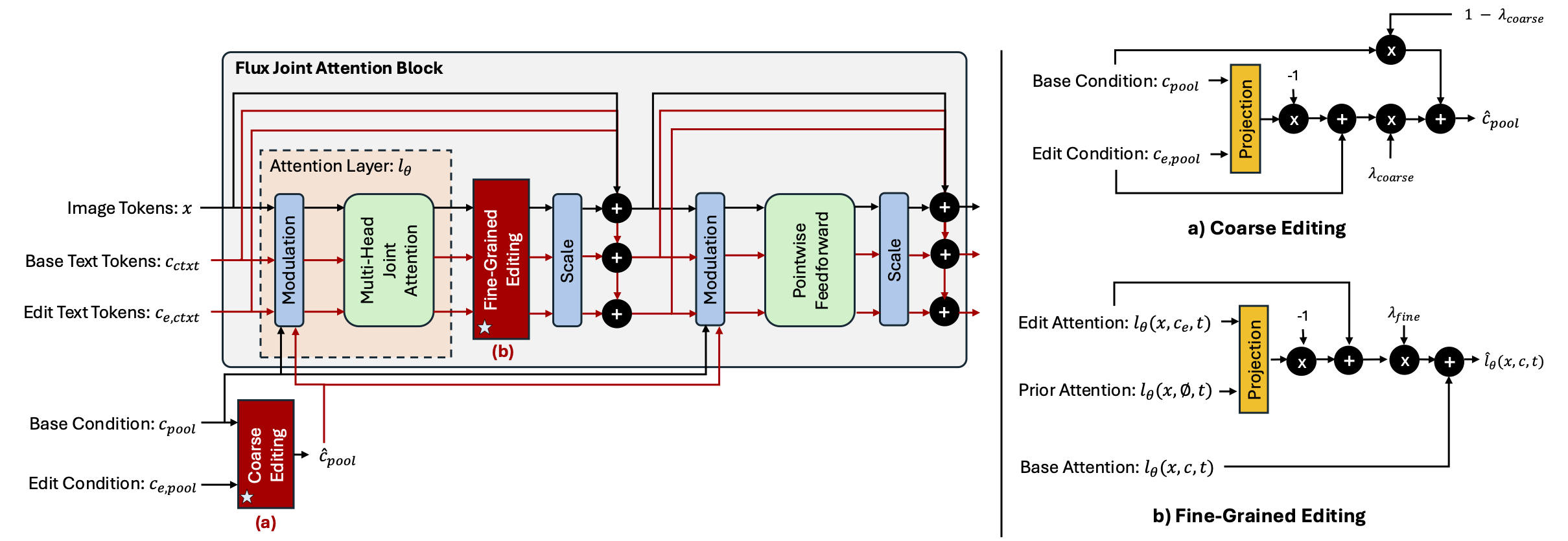
The FluxSpace framework introduces a dual-level editing scheme within the joint transformer blocks of Flux, enabling coarse and fine-grained visual editing. Coarse editing operates on pooled representations of base (cpool) and edit (ce, pool) conditions, allowing global changes like stylization, controlled by the scale λcoarse (a). For fine-grained editing, we define a linear editing scheme using base, prior and edit attention outputs, guided by scale λcontext (b). With this dual level design, our framework is both able to perform coarse-level and fine-grained editing, with a linearly adjustable scale.
Editing Results
Face Editing with Different Concepts

Our method is able to perform a variety edits from fine grained face editing (e.g. adding eyeglasses) to changes over the overall structure of the image (e.g. comics style).
Editing with Multiple Subjects

In addition to images with only one subject to be edited, FluxSpace can apply edits by identifying semantics globally and editing multiple subjects at the same time.
Editing with Different Imaging Settings - Local Edits

FluxSpace is able to perform edits that result in local changes, such as adding sunglasses. Since we leverage the semantic understanding capabilities of Flux, we can precisely perform the desired edit on different imaging settings.
Editing with Different Imaging Settings - Global Edits

FluxSpace can peform edits that result in changes in global appearance. In edits such as gender, where the overall subject is bound to significant changes, our framwork can preserve edit-irrelavent details and adjust the target subject sufficiently.
BibTeX
@misc{dalva2024fluxspace,
title={FluxSpace: Disentangled Semantic Editing in Rectified Flow Transformers},
author={Yusuf Dalva and Kavana Venkatesh and Pinar Yanardag},
year={2024},
eprint={2412.09611},
archivePrefix={arXiv},
primaryClass={cs.CV}
}